이벤트 전파
DOM 트리 상에 존재하는 DOM 요소 노드에서 발생한 이벤트가 DOM 트리를 통해 전파되는 것을 말한다.
이벤트 전파는 이벤트 객체가 전파되는 방향에 따라 3단계로 구분할 수 있다.1
- 캡쳐링 단계(capturing phase) : 이벤트가 상위 요소 -> 하위 요소 방향으로 전파
- 타깃 단계(target phase) : 이벤트가 이벤트 타깃에 도달
- 버블링 단계(bubbling phase) : 이벤트가 하위 요소 -> 상위 요소 방향으로 전파
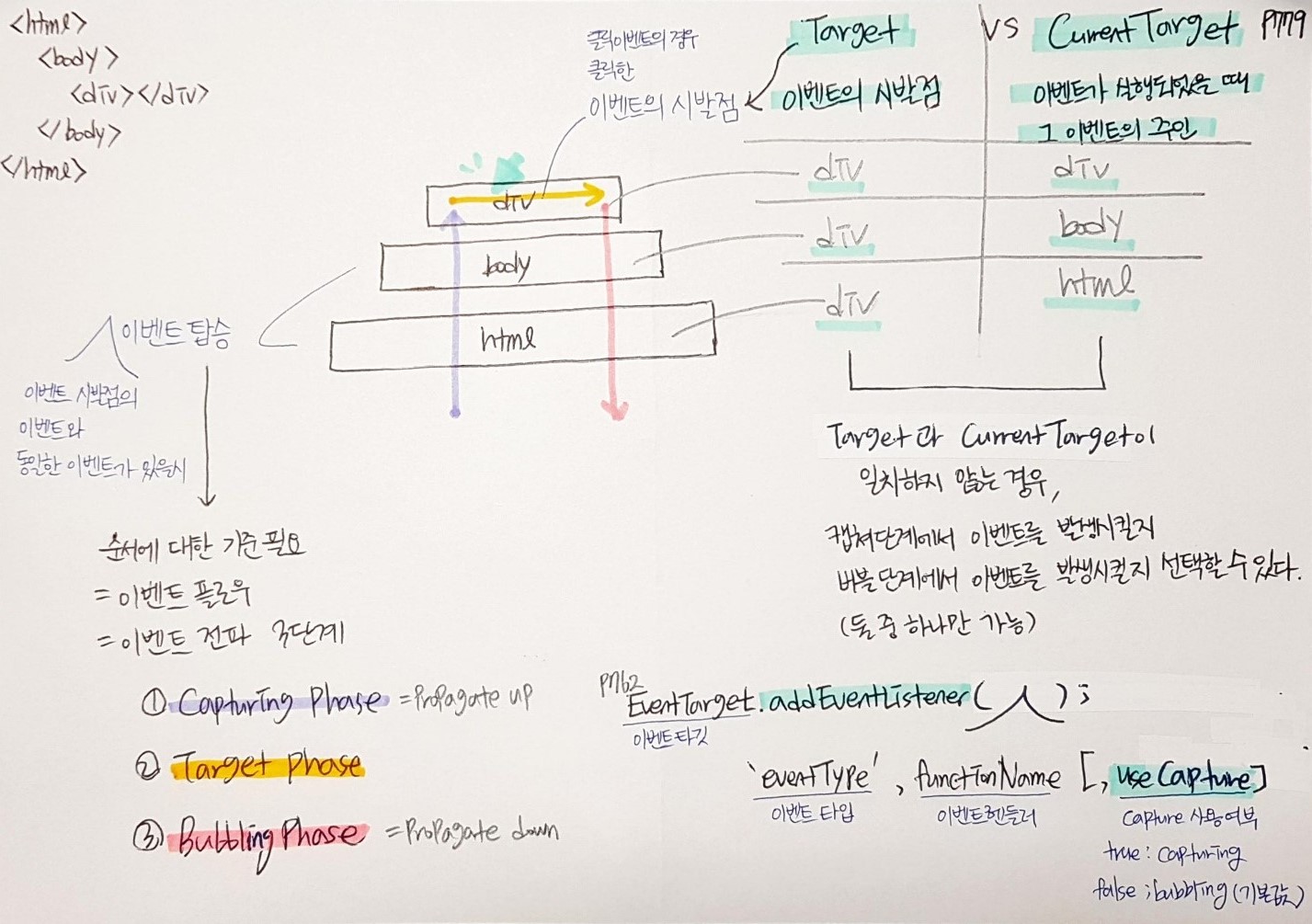
클릭 이벤트를 예시로 그림1을 보면, div를 클릭했기 때문에 클릭 이벤트의 시발점은 div가 된다.
이 때, body와 html 등 클릭 이벤트의 상위 요소에 이벤트 시발점의 이벤트와 동일한 이벤트가 존재한다면, 그 이벤트들도 탑승하게 된다.
이처럼 하나의 이벤트가 발생했을 때, 다른 이벤트들도 영향을 받아 실행될 수 있어 그 이벤트들의 순서에 대한 기준이 필요하다.
그 기준이 이벤트 플로우, 이벤트 전파이다.
이벤트 전파는 캡쳐링 단계 -> 타깃 단계 -> 버블링 단계 순으로 진행된다.
target vs currentTarget
target은 이벤트 전파를 발생시킨, 이벤트 시발점이다.
그림1에서 보면, 모든 이벤트 전파의 시발점이 div이므로 div객체의 이벤트에서도 div이고, body객체의 이벤트와 html객체의 이벤트에서도 div이다.
currentTarget은 어떤 이벤트가 실행되었을 때, 그 이벤트의 주인이다.
그럼1에서 보면, div객체의 이벤트는 div객체의 것이고, body객체의 이벤트는 body객체의 것, html객체의 이벤트는 html객체의 것이므로, 순서대로 div, body, html이 된다.
target과 currentTarget이 일치하는 경우, 이벤트 전파 단계 중 2. 타깃 단계(target phase)에서 실행된다.
target과 currentTarget이 일치하지 않는 경우, 1. 캡쳐링 단계(capturing phase)와 3. 버블링 단계(bubbling phase) 중 어느 단계에서 발생시킬 지 선택할 수 있다. (택1이다.)
선택하는 방법은 아래와 같이 addEventListener()를 사용하여 이벤트를 등록할 때, 필수가 아닌 옵션 매개변수인 useCapture를 이용하는 것이다.
useCapture에 인수를 할당하지 않으면, 기본값 false로 들어가 3. 버블링 단계(bubbling phase)에서 이벤트를 발생시키겠다고 지정하는 것이다.
true를 넣어주면 캡쳐링 단계(capturing phase)에서 이벤트를 발생시키겠다고 지정할 수 있다.
EventTarget.addEventListener(‘event Type’, functionName, [,useCapture])2
예시1
코드펜에서 보기
See the Pen
Event Propagation Example by HyunJungC-Dev (@hyunjungc-dev)
on CodePen.
위 코드를 실행하고 div를 클릭한다면 그림 2와 같이 이벤트 전파가 이루어진다.
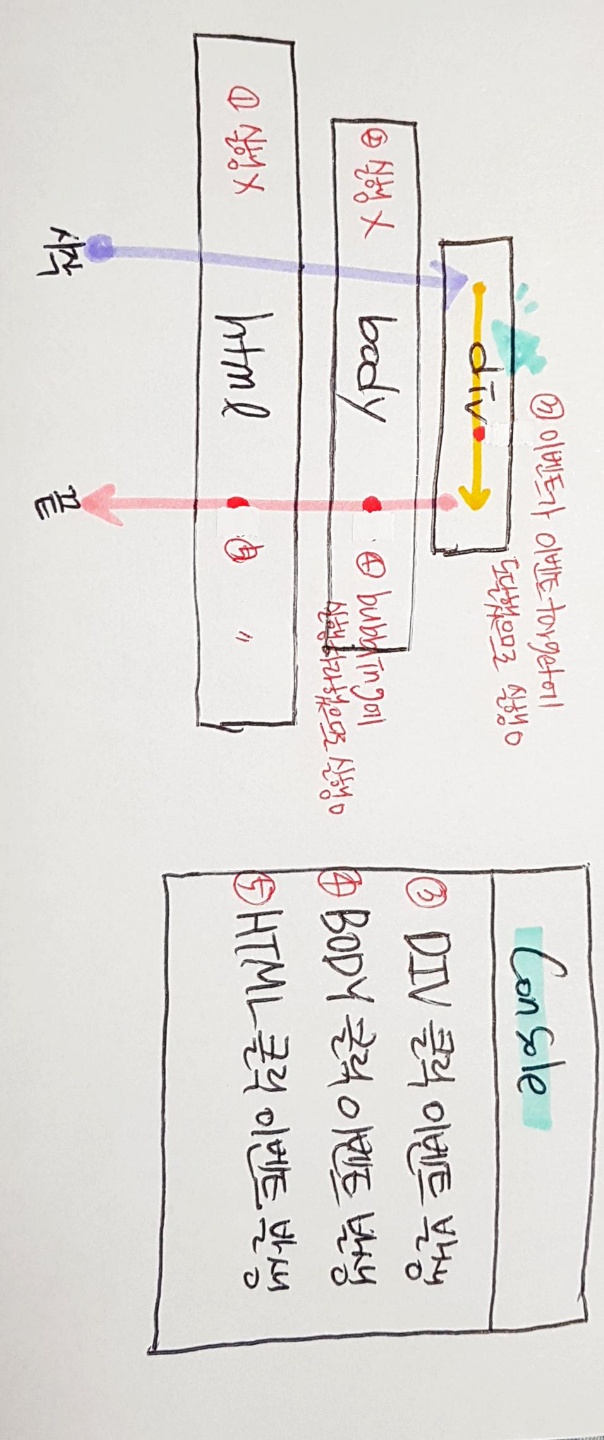
코드를 보면 div, body, html 모두 click 이벤트를 가지고 있어 div를 클릭했을 때 body와 html의 click 이벤트도 영향을 받게 된다.
addEventListener()를 보면 div, body, html 모두 useCapture에 인수가 할당되지 않으므로 기본값 false를 가진다.
따라서 target과 currentTarget이 일치하지 않는 body와 html의 경우 3. 버블링 단계(bubbling phase)에서 이벤트를 발생시키도록 코딩되어 있다.
div는 target과 currentTarget이 일치하므로, 2. 타깃 단계(target phase)에서 이벤트를 발생시킨다.
이벤트 전파는 항상 1. 캡쳐링 단계(capturing phase) -> 2. 타깃 단계(target phase) -> 3. 버블링 단계(bubbling phase) 순서대로 이루어진다.
위의 경우, 1. 캡쳐링 단계(capturing phase)에서 실행될 이벤트는 없다.
다음으로, 2. 타깃 단계(target phase)에서 div의 click 이벤트가 실행되어 Console에 ‘DIV 클릭 이벤트 발생’이라는 문자열을 찍게 된다.
마지막으로 3. 버블링 단계(bubbling phase)에서는 하위 요소->상위 요소 방향으로 진행되므로 body의 click 이벤트가 먼저 실행되어 Console에 ‘BODY 클릭 이벤트 발생’이라는 문자열을 찍는다. 그 다음 html의 click 이벤트가 실행되어 Console에 ‘HTML 클릭 이벤트 발생’이라는 문자열을 찍게 된다.
예시2
그럼 div가 아닌 body를 클릭하면 어떻게 될까?
그림 3과 같은 순서대로 이벤트 전파, 이벤트 실행이 일어나게 된다.
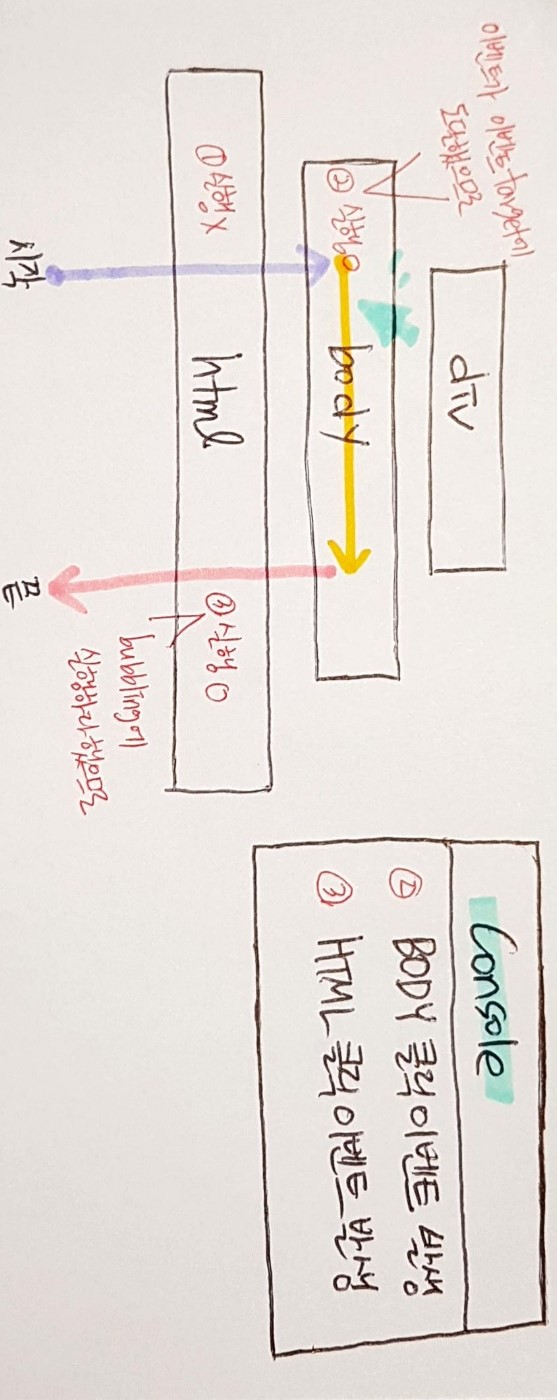
예시3
코드펜에서 보기
See the Pen
Event Propagation Example01 by HyunJungC-Dev (@hyunjungc-dev)
on CodePen.
이제 1. 캡쳐링 단계(capturing phase)에 실행되는 이벤트가 있는 경우를 보자.
코드를 보면 body.addListener()의 useCapture에 true를 넘겨준다. 즉, body의 이벤트는 1. 캡쳐링 단계(capturing phase)에 실행되도록 설정했다.
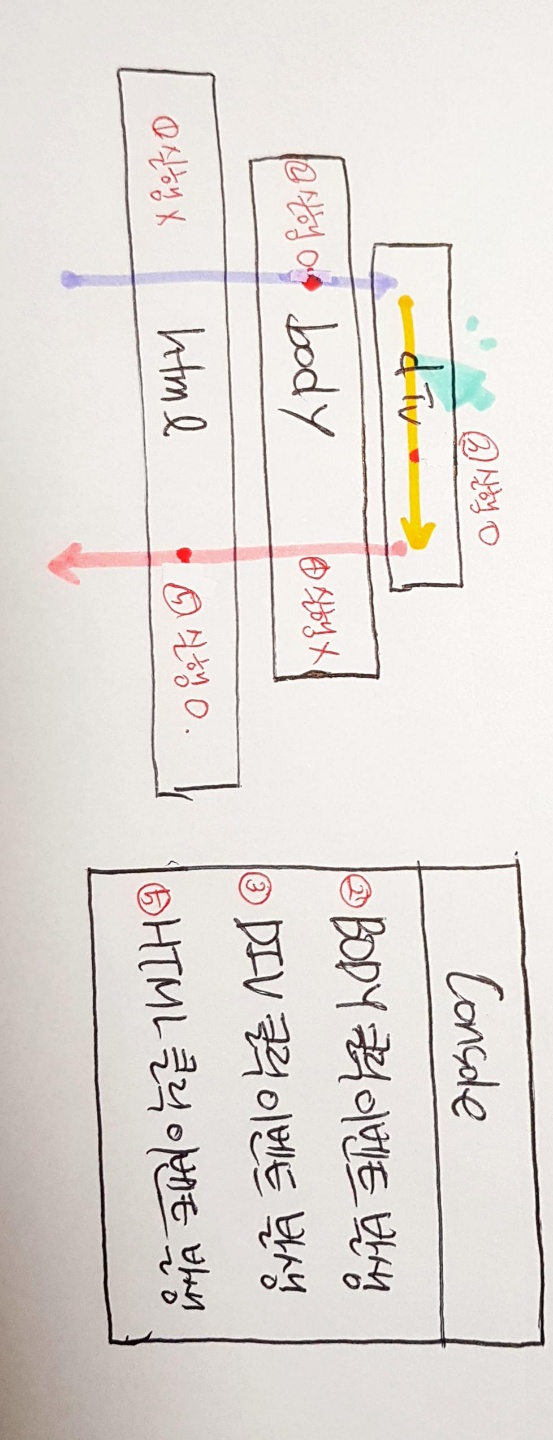
그러면 그림 4와 같이 1. 캡쳐링 단계(capturing phase)에서 body의 이벤트 객체가 실행되고, 2. 타깃 단계(target phase)에서 div의 이벤트 객체가 실행된다. 그리고 마지막으로 3. 버블링 단계(bubbling phase)에서 html의 이벤트 객체가 실행되어 Console에는 ‘BODY 클릭 이벤트 발생’, ‘DIV 클릭 이벤트 발생’, ‘HTML 클릭 이벤트 발생’ 순으로 찍히게 된다.
착각하지 말아야할 것
코드펜에서 보기
See the Pen
Event Propagation Example03 by HyunJungC-Dev (@hyunjungc-dev)
on CodePen.
1: 모던 자바스크립트 Deep Dive p779 40.6 이벤트 전파
2: MDN EventTarget.addEventListener()